
Free Online OCR
OnlineOCR.net підтримує 46 мов розпізнавання серед яких основні: англійської, російської, німецької та французької та інших європейських мов, є навіть китайський, македонський і албанський.
Сервіс може обробляти наступні формати зображень:
- PDF (всі типи файлів PDF, включаючи багатосторінкові);
- TIF/TIFF (підтримується багатосторінкове TIFF);
- JPEG/JPG;
- BMP;
- PCX;
- PNG;
- GIF;
Також можуть бути завантажені ZIP-файли, що містять вищевказані типи файлів.

Види форматів зображень
Майте на увазі, що сервіс обробляє далеко не всі зображення. Друга важлива умова — його розмір. Він не повинен перевищувати 200 Мб. Це стосується багатосторінкових PDF, але якщо ваша мета — розпізнати текст з одного або двох зображень — вам не доведеться про це турбуватися.
Примітка! Якість зображення є одним з найбільш важливих факторів, що підвищують ефективність розпізнавання. Для обробки краще всього використовувати фотографії, вирішення яких не менше 200-400 точок на дюйм для вхідних зображень.
Сервіс надає можливість конвертувати розпізнаний текст у 5 форматів виводу:
- Adobe PDF;
- Microsoft Word;
- Microsoft Excel;
- RTF;
- Звичайний текстовий документ.
Крок 1. Перейдіть на сайт онлайн сервісу. Натисніть на кнопку “Select file…”, щоб відкрити зображення з вашого комп’ютера.
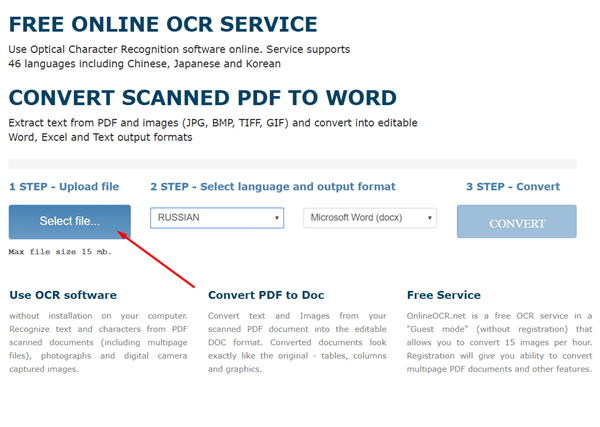
Переходимо на сайт онлайн-сервісу
Крок 2. Виберіть потрібний вам мову і відповідний формат.

Вибираємо потрібний вам мову і відповідний формат
Крок 3. Натисніть на кнопку «Convert».
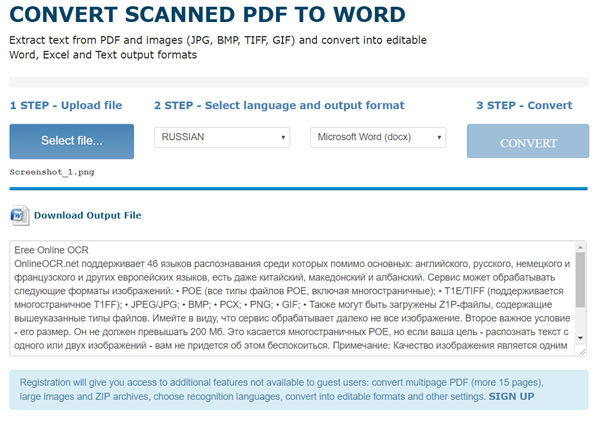
Натискаємо на кнопку «Convert»
Ви можете бачити результат розпізнавання тексту. В якості вихідного файлу використовувався скриншот фрагменту цієї статті. Оскільки в якості мови розпізнавання був обраний російський, система не змогла коректно розпізнати такі слова як Free, TIFF, ZIP та інші.





